A Trip to Binary Tree Traversal
I had a rather unconventional trip with a girl who holds a very weird yet also unique place in my heart recently.
The trip includes an early morning visit to the fish market without buying any fish, a meal with kind of disappointing sashimi at a local street vendor, a super short 5 min stroll along the cliff side when the sun rises, a nap in a low rank rented car before 8 a.m., a private beach full of advertising materials, a bunch of handpicked harmless Truth or Drink questions in a chain coffee shop, a couple of questionable stories which I don’t really buy for some reason, and several hours of drowsy driving.
While all of them are strange enough. The weirdest things are yet to be revealed. We sat in a cafe debugging the code, and the other one is me trying to explain how to traverse a binary tree while driving along the curvy seaside road under the cornflower-ish blue sky…
After a short pause in a cafe at our last destination, I asked her if she still want me to explain how binary tree works? She refused. For being considerate about me driving hours since the midnight? Or she just had enough of this already way too long day trip? I don’t know. Maybe she’ll eventually figured out how to traverse a binary tree by herself or with someone’s help. But here’s how I was going to explain the binary traversal if the conversation did go on.
Binary Tree
First, a very brief explanation of binary tree. Binary tree is essentially a graph data structure, which consists of a root node, and each node has 0 to 2 child nodes. Which means each node will have pointers that point to the left and right child node. There’s several type of binary trees, but here I’m not going to dive in too deep, but only talk about general binary tree.
Binary Tree Traversal
There are two widely known methods that can help us to traverse a binary tree, Breadth-first Search and Depth-first Search. As the name suggests, the breadth-first search basically traverse each node at the same level (height) until it reaches the bottom of the tree. And the depth-first search goes to the node at the bottom of the tree, and basically search from the bottom up.
Words can be vague. Especially I’m not particularly good in English. So, let’s see them with some pictures and the code.
Depth-first Search

To break down the depth-first search algorithm, we’ll need to understand a rather annoying concept, “Recursion”.
Recursion in programming basically means a function calling itself repeately. And in computer’s world, functions executed in a specific way, which creates a stack. And that’s what we can usually see when the computer complains about our codes causing errors, it gives us a stack trace. Which shows us who calls each function until it crashed.

We can visualize it as [one(), two(), three()].
And recursion is no exception. Due to the nature of how computer works, recursion creates a call stack too.
To further elaborate how it works, let’s dive in the code.
First, we define our node structure as follow, which is kind of standard binary tree node should looks like.
type BinaryNode<T> {
value: T,
left?: BinaryNode<T>,
right?: BinaryNode<T>,
}And we walk through the tree with a recursive function.
function walk(curr: BinaryNode<number> | undefined) {
walk(curr.left);
walk(curr.right);
}This is the pseudo code for a walk function, do not try to execute it under any circumstances. You can see we recursively call the walk with the left node and the right node.
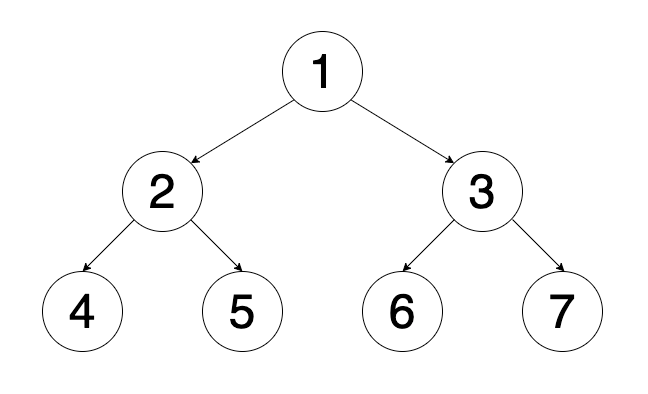
Now, we introduce the tree we are going to walk through with our code. The number on each node represent its value.
So, what will the computer execute our code with this particular tree? It will look somewhat like this…
[walk(1), walk(2), walk(4)] and there’s nothing to recurring deeper. So, we go back to node 2 and recurring to the right-hand side… [walk(1), walk(2), walk(5)]. And once again, there’s nothing to recurring deeper. So, we go back to node 1 and recurring to the right-hand side… [walk(1), walk(3), walk(6)]… And so on…
So, you can kind of see it’s a stack. We keep pushing the walk function into the call stack, and when we reach the end of a branch, we pop back to the latest node. Typical FILO (First in, last out).
And since recursion have an almost life cycle alike property, which allow us to do the things we want to do in pre recursion, in recursion and post recursion. As you probably heard depth-first search has pre-order traversal, in-order traversal and post-order traversal.
So, how does that work? Let’s jump back to the code.
function walk(curr: BinaryNode<number> | undefined) {
// pre recursion
// recursion
walk(curr.left);
walk(curr.right);
// post recursion
}I marked some comments in the original code that indicates when does each “life cycle” take place. For whom don’t really actually know how recursion works, they probably don’t know their existence. But once you know this little secret, it does help a lot.
In the world of node traversing, we call the function we are going to execute as visit. Just to make things easier, our visit function only print out the value of the node.
function visit(curr: BinaryNode<number> | undefined) {
console.log(curr?.value)
}
function walk(curr: BinaryNode<number> | undefined) {
// pre recursion
visit(curr)
// recursion
walk(curr.left);
walk(curr.right);
// post recursion
}And this is what we called pre-order traversal, because the visit happened before the recursion.
So, what will it happened when we run it? Well, we print out the value immediately when we go through each node. In this case, the output will be [1, 2, 4, 5, 3, 6, 7].
function visit(curr: BinaryNode<number> | undefined) {
console.log(curr?.value)
}
function walk(curr: BinaryNode<number> | undefined) {
// pre recursion
// recursion
walk(curr.left);
visit(curr)
walk(curr.right);
// post recursion
}Next, in-order traversal. We put our visit function in between of the recursions. So, the value will only be printed when left-hand side has been walked thoroughly and before the right-hand side start to recurring. The output will be [4, 2, 5, 1, 6, 3, 7].
function visit(curr: BinaryNode<number> | undefined) {
console.log(curr?.value)
}
function walk(curr: BinaryNode<number> | undefined) {
// pre recursion
// recursion
walk(curr.left);
walk(curr.right);
// post recursion
visit(curr)
}Lastly, the post-order traversal. Since the visit happened after left and right recursions. So, we’ll print out the last traversed node, which should be the node at bottom right, almost like in a backward manner. The output will look like [7, 6, 3, 5, 4, 2, 1].
And if you put the outputs of three different orders together…
[1, 2, 4, 5, 3, 6, 7]
[4, 2, 5, 1, 6, 3, 7]
[7, 6, 3, 5, 4, 2, 1]
You can probably notice that the root node (value 1) is printed exactly at the first, middle and the last position in different traverse strategy.
While different traverse order does have different purposes, but I’m not going to cover that for now.
And that’s it. The very basic depth-first search binary tree traversal.
The key takeaway is know your recursion, nothing really magical or special.
Breadth-first Search
We utilize our knowledge of stack for depth-first search. So, what about breadth-first search?
We can make it a queue!
As we already know queue is the opposite of stack, which works in a FIFO (First in, first out) manner. So, how does that going to help? Let’s use the same binary tree to demonstrate the idea.
Imagine we have an [1], which is a queue by the way. At each iteration, we take the first item out, and push its left and right child nodes into the queue… Not quite yet? Let’s see how it will look like at each iteration.
// 1 iteration
[1]
// 2 iteration: take out 1, and push 2, 3
[2, 3]
// 3 iteration: take out 2, and push 4, 5
[3, 4, 5]
// 4 iteration: take out 3, and push 6, 7
[4, 5, 6, 7]
// 5 iteration: take out 4, nothing to push into queue since 4 is the terminus node
[5, 6, 7]
// 6 iteration: take out 5, nothing to push into queue since 5 is the terminus node
[6, 7]
// 7 iteration: take out 6, nothing to push into queue since 6 is the terminus node
[7]
// 8 iteration: take out 7, nothing to push into queue since 7 is the terminus node
[]
// The output will be
[1, 2, 3, 4, 5, 6, 7, 8]Personally, I think the idea behind the breadth-first search is much simpler, since we don’t have to deal with recursion. All we need is good old loop. Let’s try to make it happened in the pseudo code.
function walk(root: BinaryNode<number>): void {
const queue: (BinaryNode<number> | undefined)[] = [root];
while(q.length) {
// take out the first item
const curr = q.shift();
// push its left and right child nodes into the queue
q.push(curr.left);
q.push(curr.right);
}
}That’s it! And again, do not try to run it… If we want to visit the node, we can put our visit function right after the q.shift(). Like if we are trying to search something, you can have an if statement to check if curr.value equals to something we are looking for. It’s just that simple.
So, next time if a girl ever asked you how to traverse a binary tree, you know how to explain to her.
Although I find it rarely happened in anyone’s life. But it does happened in mine. So, I guess nothing is impossible…